# imports that I'll use over the course of the project
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import cross_val_score, cross_val_predict, train_test_split, KFold
from sklearn.linear_model import LinearRegression, Lasso
from sklearn.metrics import r2_score
%matplotlib inline
# read in data
houses = pd.read_csv('./data/train.csv')
holdout_set = pd.read_csv('./data/test.csv')
Basic EDA
# Check out the data types
houses.dtypes
Id int64
PID int64
MS SubClass int64
MS Zoning object
Lot Frontage float64
Lot Area int64
Street object
Alley object
Lot Shape object
Land Contour object
Utilities object
Lot Config object
Land Slope object
Neighborhood object
Condition 1 object
Condition 2 object
Bldg Type object
House Style object
Overall Qual int64
Overall Cond int64
Year Built int64
Year Remod/Add int64
Roof Style object
Roof Matl object
Exterior 1st object
Exterior 2nd object
Mas Vnr Type object
Mas Vnr Area float64
Exter Qual object
Exter Cond object
...
Half Bath int64
Bedroom AbvGr int64
Kitchen AbvGr int64
Kitchen Qual object
TotRms AbvGrd int64
Functional object
Fireplaces int64
Fireplace Qu object
Garage Type object
Garage Yr Blt float64
Garage Finish object
Garage Cars float64
Garage Area float64
Garage Qual object
Garage Cond object
Paved Drive object
Wood Deck SF int64
Open Porch SF int64
Enclosed Porch int64
3Ssn Porch int64
Screen Porch int64
Pool Area int64
Pool QC object
Fence object
Misc Feature object
Misc Val int64
Mo Sold int64
Yr Sold int64
Sale Type object
SalePrice int64
Length: 81, dtype: object
# Basic description to check any weirdness
houses.describe().T
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| Id | 2051.0 | 1.474034e+03 | 8.439808e+02 | 1.0 | 753.5 | 1486.0 | 2.198000e+03 | 2930.0 |
| PID | 2051.0 | 7.135900e+08 | 1.886918e+08 | 526301100.0 | 528458140.0 | 535453200.0 | 9.071801e+08 | 924152030.0 |
| MS SubClass | 2051.0 | 5.700878e+01 | 4.282422e+01 | 20.0 | 20.0 | 50.0 | 7.000000e+01 | 190.0 |
| Lot Frontage | 1721.0 | 6.905520e+01 | 2.326065e+01 | 21.0 | 58.0 | 68.0 | 8.000000e+01 | 313.0 |
| Lot Area | 2051.0 | 1.006521e+04 | 6.742489e+03 | 1300.0 | 7500.0 | 9430.0 | 1.151350e+04 | 159000.0 |
| Overall Qual | 2051.0 | 6.112140e+00 | 1.426271e+00 | 1.0 | 5.0 | 6.0 | 7.000000e+00 | 10.0 |
| Overall Cond | 2051.0 | 5.562165e+00 | 1.104497e+00 | 1.0 | 5.0 | 5.0 | 6.000000e+00 | 9.0 |
| Year Built | 2051.0 | 1.971709e+03 | 3.017789e+01 | 1872.0 | 1953.5 | 1974.0 | 2.001000e+03 | 2010.0 |
| Year Remod/Add | 2051.0 | 1.984190e+03 | 2.103625e+01 | 1950.0 | 1964.5 | 1993.0 | 2.004000e+03 | 2010.0 |
| Mas Vnr Area | 2029.0 | 9.969591e+01 | 1.749631e+02 | 0.0 | 0.0 | 0.0 | 1.610000e+02 | 1600.0 |
| BsmtFin SF 1 | 2050.0 | 4.423005e+02 | 4.612041e+02 | 0.0 | 0.0 | 368.0 | 7.337500e+02 | 5644.0 |
| BsmtFin SF 2 | 2050.0 | 4.795902e+01 | 1.650009e+02 | 0.0 | 0.0 | 0.0 | 0.000000e+00 | 1474.0 |
| Bsmt Unf SF | 2050.0 | 5.677283e+02 | 4.449548e+02 | 0.0 | 220.0 | 474.5 | 8.110000e+02 | 2336.0 |
| Total Bsmt SF | 2050.0 | 1.057988e+03 | 4.494107e+02 | 0.0 | 793.0 | 994.5 | 1.318750e+03 | 6110.0 |
| 1st Flr SF | 2051.0 | 1.164488e+03 | 3.964469e+02 | 334.0 | 879.5 | 1093.0 | 1.405000e+03 | 5095.0 |
| 2nd Flr SF | 2051.0 | 3.293291e+02 | 4.256710e+02 | 0.0 | 0.0 | 0.0 | 6.925000e+02 | 1862.0 |
| Low Qual Fin SF | 2051.0 | 5.512921e+00 | 5.106887e+01 | 0.0 | 0.0 | 0.0 | 0.000000e+00 | 1064.0 |
| Gr Liv Area | 2051.0 | 1.499330e+03 | 5.004478e+02 | 334.0 | 1129.0 | 1444.0 | 1.728500e+03 | 5642.0 |
| Bsmt Full Bath | 2049.0 | 4.275256e-01 | 5.226732e-01 | 0.0 | 0.0 | 0.0 | 1.000000e+00 | 3.0 |
| Bsmt Half Bath | 2049.0 | 6.344558e-02 | 2.517052e-01 | 0.0 | 0.0 | 0.0 | 0.000000e+00 | 2.0 |
| Full Bath | 2051.0 | 1.577279e+00 | 5.492794e-01 | 0.0 | 1.0 | 2.0 | 2.000000e+00 | 4.0 |
| Half Bath | 2051.0 | 3.710385e-01 | 5.010427e-01 | 0.0 | 0.0 | 0.0 | 1.000000e+00 | 2.0 |
| Bedroom AbvGr | 2051.0 | 2.843491e+00 | 8.266183e-01 | 0.0 | 2.0 | 3.0 | 3.000000e+00 | 8.0 |
| Kitchen AbvGr | 2051.0 | 1.042906e+00 | 2.097900e-01 | 0.0 | 1.0 | 1.0 | 1.000000e+00 | 3.0 |
| TotRms AbvGrd | 2051.0 | 6.435885e+00 | 1.560225e+00 | 2.0 | 5.0 | 6.0 | 7.000000e+00 | 15.0 |
| Fireplaces | 2051.0 | 5.909313e-01 | 6.385163e-01 | 0.0 | 0.0 | 1.0 | 1.000000e+00 | 4.0 |
| Garage Yr Blt | 1937.0 | 1.978708e+03 | 2.544109e+01 | 1895.0 | 1961.0 | 1980.0 | 2.002000e+03 | 2207.0 |
| Garage Cars | 2050.0 | 1.776585e+00 | 7.645374e-01 | 0.0 | 1.0 | 2.0 | 2.000000e+00 | 5.0 |
| Garage Area | 2050.0 | 4.736717e+02 | 2.159346e+02 | 0.0 | 319.0 | 480.0 | 5.760000e+02 | 1418.0 |
| Wood Deck SF | 2051.0 | 9.383374e+01 | 1.285494e+02 | 0.0 | 0.0 | 0.0 | 1.680000e+02 | 1424.0 |
| Open Porch SF | 2051.0 | 4.755680e+01 | 6.674724e+01 | 0.0 | 0.0 | 27.0 | 7.000000e+01 | 547.0 |
| Enclosed Porch | 2051.0 | 2.257192e+01 | 5.984511e+01 | 0.0 | 0.0 | 0.0 | 0.000000e+00 | 432.0 |
| 3Ssn Porch | 2051.0 | 2.591419e+00 | 2.522961e+01 | 0.0 | 0.0 | 0.0 | 0.000000e+00 | 508.0 |
| Screen Porch | 2051.0 | 1.651146e+01 | 5.737420e+01 | 0.0 | 0.0 | 0.0 | 0.000000e+00 | 490.0 |
| Pool Area | 2051.0 | 2.397855e+00 | 3.778257e+01 | 0.0 | 0.0 | 0.0 | 0.000000e+00 | 800.0 |
| Misc Val | 2051.0 | 5.157435e+01 | 5.733940e+02 | 0.0 | 0.0 | 0.0 | 0.000000e+00 | 17000.0 |
| Mo Sold | 2051.0 | 6.219893e+00 | 2.744736e+00 | 1.0 | 4.0 | 6.0 | 8.000000e+00 | 12.0 |
| Yr Sold | 2051.0 | 2.007776e+03 | 1.312014e+00 | 2006.0 | 2007.0 | 2008.0 | 2.009000e+03 | 2010.0 |
| SalePrice | 2051.0 | 1.814697e+05 | 7.925866e+04 | 12789.0 | 129825.0 | 162500.0 | 2.140000e+05 | 611657.0 |
# Understand the size of the data
houses.shape
(2051, 81)
# Null value check
df_nulls = pd.DataFrame(data=houses.isnull().sum(), columns=['Nulls'])
df_nulls.sort_values('Nulls', ascending=False)
# There seems to be quite a few null values, should look at cleaning these up.
| Nulls | |
|---|---|
| Pool QC | 2042 |
| Misc Feature | 1986 |
| Alley | 1911 |
| Fence | 1651 |
| Fireplace Qu | 1000 |
| Lot Frontage | 330 |
| Garage Finish | 114 |
| Garage Qual | 114 |
| Garage Yr Blt | 114 |
| Garage Cond | 114 |
| Garage Type | 113 |
| Bsmt Exposure | 58 |
| BsmtFin Type 2 | 56 |
| BsmtFin Type 1 | 55 |
| Bsmt Cond | 55 |
| Bsmt Qual | 55 |
| Mas Vnr Area | 22 |
| Mas Vnr Type | 22 |
| Bsmt Half Bath | 2 |
| Bsmt Full Bath | 2 |
| Garage Area | 1 |
| Total Bsmt SF | 1 |
| Bsmt Unf SF | 1 |
| BsmtFin SF 2 | 1 |
| BsmtFin SF 1 | 1 |
| Garage Cars | 1 |
| Mo Sold | 0 |
| Sale Type | 0 |
| Full Bath | 0 |
| Half Bath | 0 |
| ... | ... |
| MS Zoning | 0 |
| Lot Area | 0 |
| Street | 0 |
| Lot Shape | 0 |
| Land Contour | 0 |
| Utilities | 0 |
| Lot Config | 0 |
| Land Slope | 0 |
| Neighborhood | 0 |
| Condition 1 | 0 |
| Condition 2 | 0 |
| Bldg Type | 0 |
| House Style | 0 |
| Overall Cond | 0 |
| 2nd Flr SF | 0 |
| Year Built | 0 |
| Year Remod/Add | 0 |
| Roof Style | 0 |
| Roof Matl | 0 |
| Exterior 1st | 0 |
| Exterior 2nd | 0 |
| Exter Qual | 0 |
| Exter Cond | 0 |
| Foundation | 0 |
| PID | 0 |
| Heating QC | 0 |
| Central Air | 0 |
| Electrical | 0 |
| 1st Flr SF | 0 |
| SalePrice | 0 |
81 rows × 1 columns
# If and when I wanna drop all na's from original DF:
# houses.dropna(axis=0, how='any')
# houses.select_dtypes(object)
Feature Engineering
Create Dummy Variables
# Setup dummy variables for later
houses_object_columns = pd.get_dummies(houses,columns=houses.select_dtypes(object).columns)
houses_object_columns.head()
| Id | PID | MS SubClass | Lot Frontage | Lot Area | Overall Qual | Overall Cond | Year Built | Year Remod/Add | Mas Vnr Area | ... | Misc Feature_TenC | Sale Type_COD | Sale Type_CWD | Sale Type_Con | Sale Type_ConLD | Sale Type_ConLI | Sale Type_ConLw | Sale Type_New | Sale Type_Oth | Sale Type_WD | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 109 | 533352170 | 60 | NaN | 13517 | 6 | 8 | 1976 | 2005 | 289.0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 1 | 544 | 531379050 | 60 | 43.0 | 11492 | 7 | 5 | 1996 | 1997 | 132.0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 2 | 153 | 535304180 | 20 | 68.0 | 7922 | 5 | 7 | 1953 | 2007 | 0.0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 3 | 318 | 916386060 | 60 | 73.0 | 9802 | 5 | 5 | 2006 | 2007 | 0.0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 4 | 255 | 906425045 | 50 | 82.0 | 14235 | 6 | 8 | 1900 | 1993 | 0.0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
5 rows × 292 columns
df_nulls_obj = pd.DataFrame(data=houses_object_columns.isnull().sum(), columns=['Nulls'])
df_nulls_obj.sort_values('Nulls', ascending=False)
| Nulls | |
|---|---|
| Lot Frontage | 330 |
| Garage Yr Blt | 114 |
| Mas Vnr Area | 22 |
| Bsmt Half Bath | 2 |
| Bsmt Full Bath | 2 |
| BsmtFin SF 1 | 1 |
| Garage Area | 1 |
| Total Bsmt SF | 1 |
| Bsmt Unf SF | 1 |
| BsmtFin SF 2 | 1 |
| Garage Cars | 1 |
| Bsmt Exposure_No | 0 |
| BsmtFin Type 1_ALQ | 0 |
| BsmtFin Type 1_BLQ | 0 |
| BsmtFin Type 1_GLQ | 0 |
| Bsmt Exposure_Gd | 0 |
| Bsmt Exposure_Mn | 0 |
| Id | 0 |
| Bsmt Exposure_Av | 0 |
| Bsmt Cond_TA | 0 |
| Bsmt Cond_Po | 0 |
| Bsmt Cond_Fa | 0 |
| Bsmt Cond_Ex | 0 |
| Bsmt Qual_TA | 0 |
| Bsmt Qual_Po | 0 |
| Bsmt Qual_Gd | 0 |
| Bsmt Qual_Fa | 0 |
| Bsmt Cond_Gd | 0 |
| BsmtFin Type 1_Unf | 0 |
| BsmtFin Type 1_LwQ | 0 |
| ... | ... |
| Neighborhood_Timber | 0 |
| Neighborhood_StoneBr | 0 |
| Neighborhood_Somerst | 0 |
| Neighborhood_SawyerW | 0 |
| Neighborhood_SWISU | 0 |
| Bldg Type_2fmCon | 0 |
| Neighborhood_OldTown | 0 |
| Neighborhood_NridgHt | 0 |
| Neighborhood_NoRidge | 0 |
| Neighborhood_NWAmes | 0 |
| Neighborhood_NPkVill | 0 |
| Neighborhood_NAmes | 0 |
| Condition 1_Feedr | 0 |
| Condition 1_Norm | 0 |
| Condition 1_PosA | 0 |
| Condition 1_PosN | 0 |
| Condition 1_RRAe | 0 |
| Condition 1_RRAn | 0 |
| Condition 1_RRNe | 0 |
| Condition 1_RRNn | 0 |
| Condition 2_Artery | 0 |
| Condition 2_Feedr | 0 |
| Condition 2_Norm | 0 |
| Condition 2_PosA | 0 |
| Condition 2_PosN | 0 |
| Condition 2_RRAe | 0 |
| Condition 2_RRAn | 0 |
| Condition 2_RRNn | 0 |
| Bldg Type_1Fam | 0 |
| Sale Type_WD | 0 |
292 rows × 1 columns
# Clean up NAN
houses_object_columns.fillna(value=0, inplace=True)
First run of features
# Most of the code after the features section was run multiple times to attempt to find the best model
# Original run of feature engineering
# Just randomly picking a few potential predictors
features = ['Lot Area', 'Overall Qual','Fireplaces','TotRms AbvGrd']
X = houses[features]
y = houses['SalePrice']
Second run of features
# I'm going to pull out only numeric columns, to see if there's some variables with high correlation that I can throw in to improve my model.
# Make it into it's own DF to run some EDA on it
houses_numonly = houses.select_dtypes(np.number)
# houses_numonly_dropna = houses_numonly.dropna(axis=0, how='any')
# houses_numonly_dropna.isnull().sum()
# Original run
# houses_numonly.columns
houses_numonly.shape
# For original run of determining correlations
features = houses_numonly.columns
X = houses[features]
y = houses_numonly['SalePrice']
# X.corr() is far too painful to look at here
# Run the heatmap, see if anything sticks out
plt.subplots(figsize=(40,30))
sns.heatmap(X.corr(), annot=True)
# Just eyeballing it, some important correlations I see (descending):
# I stopped at 'Garage Yr Blt', which had a correlation of .53
# Upon further review, 'Garage Yr Blt' had far too many missing data points, so was left off
features = ['Overall Qual',
'Gr Liv Area',
'Garage Cars',
'Garage Area',
'Total Bsmt SF',
'1st Flr SF',
'Year Built',
'Year Remod/Add',
'Full Bath']
# 'Garage Yr Blt']
Third run of features
# Third time around: going to add a few variables - might cause overfit, but let's see
# Was more lax on what variables I added (based on correlation > .3)
features = ['Overall Qual',
'Gr Liv Area',
'Garage Cars',
'Garage Area',
'Total Bsmt SF',
'1st Flr SF',
'Year Built',
'Year Remod/Add',
'Full Bath',
'TotRms AbvGrd',
'Mas Vnr Area',
'Fireplaces',
'BsmtFin SF 1',
'Wood Deck SF']
Code below was run on multiple sets of features
# Set your in/dependent variables
# Original usage
# X = houses[features]
# y = houses['SalePrice']
# Old run:
# X = houses_object_columns[features]
# y = houses_object_columns['SalePrice']
# Null check
X.isnull().sum()
# Fill in the nas:
# Despite the warning, this still works:
X['Mas Vnr Area'].fillna(value=0, inplace=True)
X['Garage Cars'].fillna(value=0, inplace=True)
X['Garage Area'].fillna(value=0, inplace=True)
X['Total Bsmt SF'].fillna(value=0, inplace=True)
X['BsmtFin SF 1'].fillna(value=0, inplace=True)
# Check:
X.isnull().sum()
# X.shape[0]
Graveyard for data cleanup
# 2nd feature run note: Going to rebuild my features, minus Grg yr blt as there seems to be more than a few nulls
# Some of the next few cells were only used for original run through of cleaning up features
# Take a look at null values in my features:
# X[X['Garage Cars'].isnull() == True]
# Looks like the singular null in 'Grg Cars' is one in the same w/ 'Grg Area'
# # Dropping the rows with the null values
# X = X.drop(X.index[1712])
# # Sets have to match in row length:
# y = y.drop(y.index[1712])
# Check to make sure it worked
# X[X['Garage Cars'].isnull() == True]
# X[X['Total Bsmt SF'].isnull() == True]
# Dropping the rows with the null values
# X = X.drop(X.index[1327])
# Sets have to match in row length:
# y = y.drop(y.index[1327])
# Check to make sure it worked
# X[X['Total Bsmt SF'].isnull() == True]
# Messing around trying to figure out how to locate the null rows
# X.columns[X.isna().any()].tolist()
# X.loc[:,X.isna().any()]
Lasso
X = houses_object_columns.drop('SalePrice', axis=1)
y = houses_object_columns['SalePrice']
# train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y)
X_train.fillna(value=0, inplace=True)
# X_test.fillna(value=0, inplace=True)
y_train.fillna(value=0, inplace=True)
# y_test.fillna(value=0, inplace=True)
L = Lasso(alpha = 2.5, max_iter=10000, random_state = 42)
L.fit(X_train, y_train)
Lasso(alpha=2.5, copy_X=True, fit_intercept=True, max_iter=10000,
normalize=False, positive=False, precompute=False, random_state=42,
selection='cyclic', tol=0.0001, warm_start=False)
# Original attempts:
# LinearRegression
# linreg = LinearRegression()
# Original fit
# linreg.fit(X, y)
# linreg.coef_
# Using KFold to help randomize the folds, and also see if different splits get me significantly different scores
kf = KFold(n_splits=5, random_state=42, shuffle=True)
scores = cross_val_score(L, X_train, y_train, cv=kf)
print(scores)
print(scores.mean())
/anaconda3/lib/python3.6/site-packages/sklearn/linear_model/coordinate_descent.py:491: ConvergenceWarning: Objective did not converge. You might want to increase the number of iterations. Fitting data with very small alpha may cause precision problems.
ConvergenceWarning)
/anaconda3/lib/python3.6/site-packages/sklearn/linear_model/coordinate_descent.py:491: ConvergenceWarning: Objective did not converge. You might want to increase the number of iterations. Fitting data with very small alpha may cause precision problems.
ConvergenceWarning)
/anaconda3/lib/python3.6/site-packages/sklearn/linear_model/coordinate_descent.py:491: ConvergenceWarning: Objective did not converge. You might want to increase the number of iterations. Fitting data with very small alpha may cause precision problems.
ConvergenceWarning)
[0.91818856 0.93117813 0.9224465 0.92833756 0.88953215]
0.9179365787394577
/anaconda3/lib/python3.6/site-packages/sklearn/linear_model/coordinate_descent.py:491: ConvergenceWarning: Objective did not converge. You might want to increase the number of iterations. Fitting data with very small alpha may cause precision problems.
ConvergenceWarning)
# Overfit
L.score(X_test, y_test)
0.6759518356006168
predictions = cross_val_predict(L, X, y, cv=kf)
plt.scatter(y, predictions)
accuracy = r2_score(y, predictions)
/anaconda3/lib/python3.6/site-packages/sklearn/linear_model/coordinate_descent.py:491: ConvergenceWarning: Objective did not converge. You might want to increase the number of iterations. Fitting data with very small alpha may cause precision problems.
ConvergenceWarning)
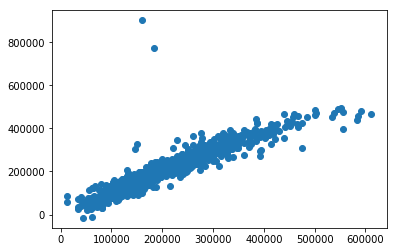
# Looks like my model is overfit
# I ran this a few times, and didn't get nearly as bad of number. Looks like there was one fold that my model was just completely ill-fitting on.
scores = cross_val_score(L, X_test, y_test, cv=kf)
print(scores)
print(scores.mean())
/anaconda3/lib/python3.6/site-packages/sklearn/linear_model/coordinate_descent.py:491: ConvergenceWarning: Objective did not converge. You might want to increase the number of iterations. Fitting data with very small alpha may cause precision problems.
ConvergenceWarning)
/anaconda3/lib/python3.6/site-packages/sklearn/linear_model/coordinate_descent.py:491: ConvergenceWarning: Objective did not converge. You might want to increase the number of iterations. Fitting data with very small alpha may cause precision problems.
ConvergenceWarning)
[ 0.76061406 -1.83481449 0.78095611 0.77575566 0.77518242]
0.25153875067533676
Code for submission to Kaggle
# Clean up and make changes along the same lines to holdout_set
holdout_set.fillna(value=0, inplace=True)
holdout_set.head(10)
X_holdout = holdout_set[features]
X_holdout.head(10)
X_holdout.isnull().sum()
# Replace one NA in Mas VNR Area
X_holdout.fillna(value=0, inplace=True)
# Original linreg
y_preds = linreg.predict(X_holdout)
# Lasso run:
y_preds = L.predict(X_holdout)
y_preds
my_ids = holdout_set['Id']
df = pd.DataFrame()
df['Id'] = my_ids
df.set_index('Id', inplace=True)
df['SalePrice'] = y_preds
%pwd
df.to_csv('./data/my_preds.csv')
Graveyard - What is dead, may never die.
# Was messing around trying to find a loop that could get me all numeric columns:
# .select_dtypes solved this issue
list_house_intFloat = []
for column in dfhouses.columns:
if dfhouses[column].dtypes == int:
# print('is int')
list_house_intFloat.append(dfhouses[column])
# elif dfhouses[column].dtypes == float:
# dfhouse_int.append(dfhouses.loc[dfhouses[column]]
# Counts for categorization of Street or Neighborhood
houses['Street'].value_counts()
# Drop na's - was using before I did it on the original set
# X.dropna(axis=0, how='any', inplace=True)
# houses_numonly_dropna = houses_numonly.dropna(axis=0, how='any')
# houses_numonly_dropna.isnull().sum()