The Internet has become the driving force of mankind’s social and economical evolution. As such, we find ourselves at the beginning of the ‘Information Age,’ where as the name seems to imply, information is king. And this information is widely available to most, and becoming more and more accessible everyday. Undoubtably, the wide availability of information has disrupted essentially all industries in one way or another, as in the past, dissymmetry of information is what gives a person or a corporation a marketable advantage.
As a result of information’s ‘reign,’ an individual that is capable of acquiring information from the Internet puts him or herself at a distinct advantage. And this is where web scrapping shows its true value!
Web scrapping is the activity of collecting structured data from the web for usage on another task or process. For data science purposes, that’s usually some type of in-depth data analysis and/or data visualization. The main purpose of this post is to breakdown the basics of web scrapping using Python for pedagogical purposes.
Useful Links:
Introduction to Key Python Libraries
To get started with web scraping in Python, there are a few libraries that you’ll need to install and import.
Note: There are additional libraries that will be required to do serious data analysis and visualization, but that are outside the scope of this post. Please see my other post for more information on: Important Python Libraries
The two most important libraries to highlight are requests and BeautifulSoup. The requests library will help us actually scrap the data from a website. Whereas BeautifulSoup helps us breakdown the html into workable chunks that we can further extract the data with and drop the html entirely.
To install:
pip install requests
pip install BeautifulSoup
Add a “!” at the beginning if doing the install directly in jupyter notebook.
Then to import the libraries:
import requests
from bs4 import BeautifulSoup
Additional Libraries of Value
By no means are these next libraries required, but they may be helpful depending on what you’re looking to accomplish. Additionally, they may help in certain circumstances where the website you’re pulling from doesn’t properly format their html (or is just simply messy or combined with redundant data).
Regex
Regex is useful in extracting data from large blocks of text on a very granular level. I should note that regex isn’t specific to just web scraping, as you can use it on any text document, nor is it specific to just Python as almost all programming language use a similar syntax.
Useful reading on regex:
- My personal favorite, as you can get practice in while learning: RegexOne
- A great resource to drop your text into and test using regex on: Regex101
- Regex Tutorial
- Regex Cheat Sheet
To install: pip install regex (add a ! at the beginning if doing it directly in jupyter notebook)
To import: Python import regex as re
Praw
If you just so happen to be interested in scrapping Reddit for information, I highly recommend looking in the library praw. Praw has built in functionality that turns scrapping Reddit into simple, mostly one-liner code blocks.
To install: pip install praw (add a ! at the beginning if doing it directly in jupyter notebook)
To import: Python import praw
Useful reading on praw:
Diving into web scrapping using Requests & BeautifulSoup
After we’ve installed and imported the necessary libraries, we can finally get started with web scrapping!
In this example, I’m going to be scraping a sports website for NHL player salary information. This is the site I’ll be using: . More specifically, the url will be (capitalized means the variable is dynamic):
First step is to set our URL, and use the .get function found in the requests library to pull the actual html.
url = "https://www.spotrac.com/nhl/rankings/2017/cap-hit/pittsburgh-penguins/"
res = requests.get(url)
Then we’ll use BeautifulSoup to breakdown the resultant text data. I instantiate a ‘soup’ object using requests.content (aliased as res above), and pass through ‘lmxl,’ which is telling BeautifulSoup what type of html parser to use.
soup = BeautifulSoup(res.content, 'lxml')
From there, we have to dig into the html on the actual website to understand how the data is actually stored. To do this, in a web browser, right-click on the piece of data you want, and click “Inspect” (the wording may be different depending on your browser). It’ll look like this (far bottom-right):
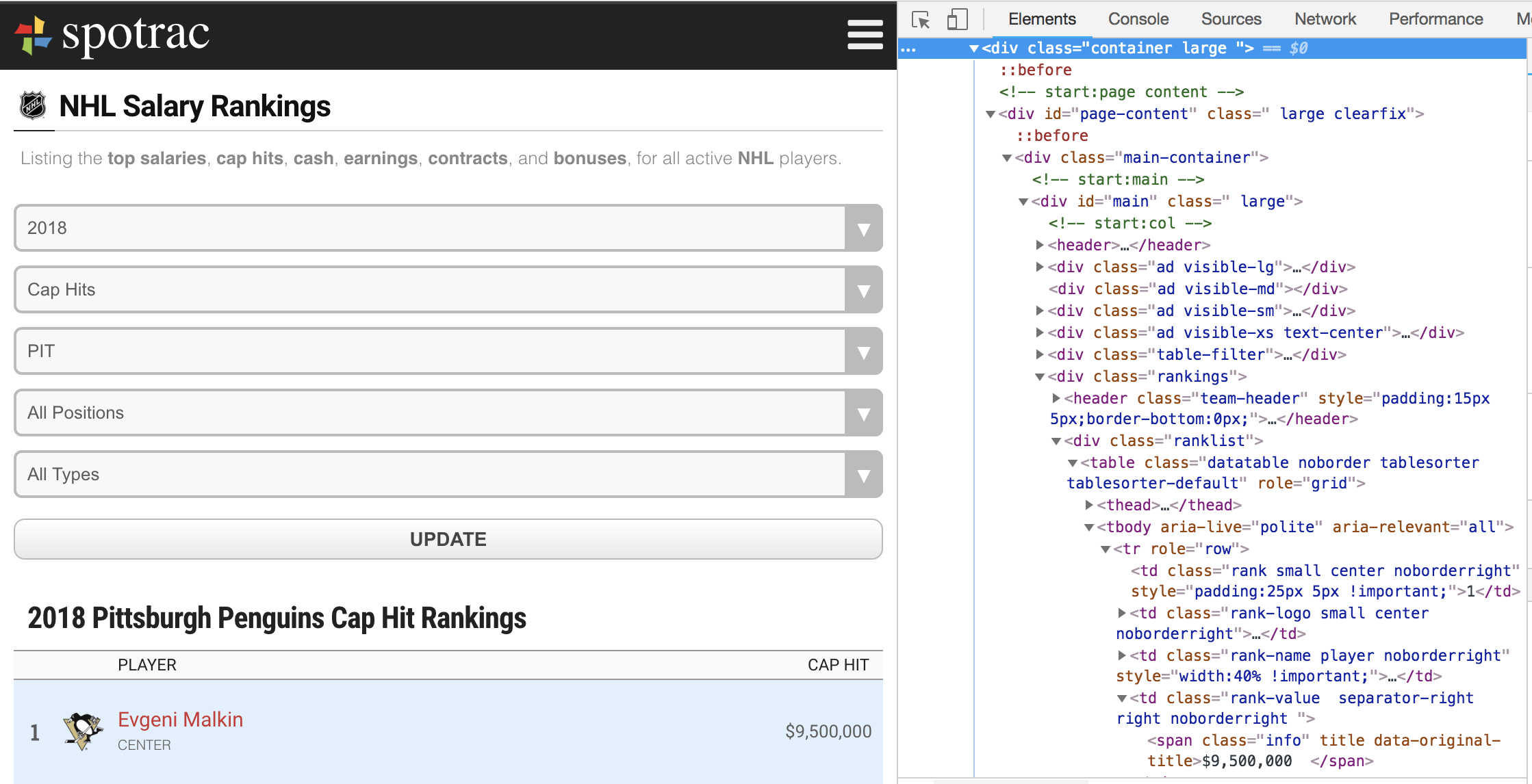
Notice the coloration in the image: the actual data we want is in black, whereas the other wrapper html text are various colors depending on what it represents. You’ve probably noticed that it’s a whole ton of information we don’t need. That’s where BeautifulSoup really shines! It’s able to interpret this and extract the information we’re looking for, leaving the html out. Specifically, we’ll use the .find_all function in BeautifulSoup:
# To pull out the player_name and cap_hit
player_name = soup.find_all('a', {'class':'team-name'})
cap_hit = soup.find_all('span', {'class':'info'})
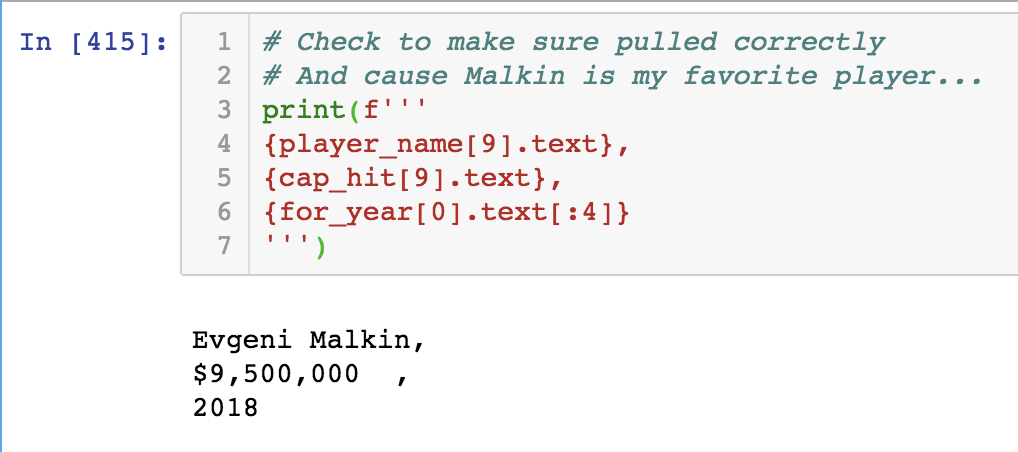
I can then index these BeautifulSoup objects with the following code to see the data extracted:
print(f'''
{player_name[9].text},
{cap_hit[9].text}
''')
Additional Steps - Using Loops to Extract Large Datasets
I created a loop based off of this to scrap the url repeatedly, for each NHL team, for each year, going back to 2011. Though I won’t be stepping through each part of this to explain, I thought it helpful to show how the above ideas can be expanded upon to really take this and run with it. I also include an additional loop example below this section for further edification.
# Scraper for salary cap info
# Create empty dataframe
df_cap = pd.DataFrame()
# Begin loop from teams created earlier
for team in teams:
# The website I'm pulling from only goes back to 2011
# And I'm not going to be using data from the still-very-young 2018-19 season, so range is 2011 to 2017
for i in range(1,8):
# Generate URL
url_base_cap_hit = ("https://www.spotrac.com/nhl/rankings/201{}/cap-hit/{}".format(i, team))
# Request get
res = requests.get(url_base_cap_hit)
# Create soup object
soup = BeautifulSoup(res.content, 'lxml')
# Pull out relevant information
player_name = soup.find_all('a', {'class':'team-name'})
cap_hit = soup.find_all('span', {'class':'info'})
# Append new data to DF
for a in range(0, len(player_name)):
df_cap = df_cap.append({'player_name': player_name[a].text,
'cap_hit': cap_hit[a].text,
'team_name':team,
'year':"201{}".format(i)}, ignore_index = True)
# To save after the loop is done
# df_cap.to_csv('cap_data_uncleaned.csv', index=True)
Web Scraping - Another Example Loop
I wanted to also include a loop that I used to scrape Reddit posts (without praw though) from the subreddit Data Science. This is to again show how we can loop through multiple pages to extract tons of data at once.
Note that I use an additional Python library known as time to cause the loop to sleep (or wait) for 3 seconds in between loops, so as not to be stopped by Reddit’s request limit. Be sure to check the website you’re scraping usage terms - they may restrict how much information you can request from their website at any one time.
# For DS set - previously ran to generate CSV
url_ds = "https://www.reddit.com/r/datascience.json"
data_ds = []
total = []
next_get = ''
# I went with 40 b/c 40 * 25 = 1000 posts total
for i in range(40):
# Request get
res = requests.get(url_ds+next_get, headers={'User-agent': 'TK Bot 0.1'})
# Convert the JSON
new_dict = res.json()
# Add to already collected data set
data_ds.extend(new_dict['data']['children'])
# Collect 'after' from new dict to generate next URL
new_url_end = str(new_dict['data']['after'])
# Generate the next URL
next_get = '?after='+new_url_end
# CSV add/update along with DF creation
# Chose greater than 0 so the else executes on the first iteration
if i > 0:
# Append new and old
total = pd.DataFrame(data_ds)
# Convert to DF and save to new csv file
pd.DataFrame(total).to_csv('data_ds.csv', index = False)
else:
pd.DataFrame(data_ds).to_csv('data_ds.csv', index = False)
# Sleep to fit within Reddit's pull limit
time.sleep(3)
That’s pretty much it! Thanks for reading!